
Self Supervised Learning for Gravitational Waves
Context:
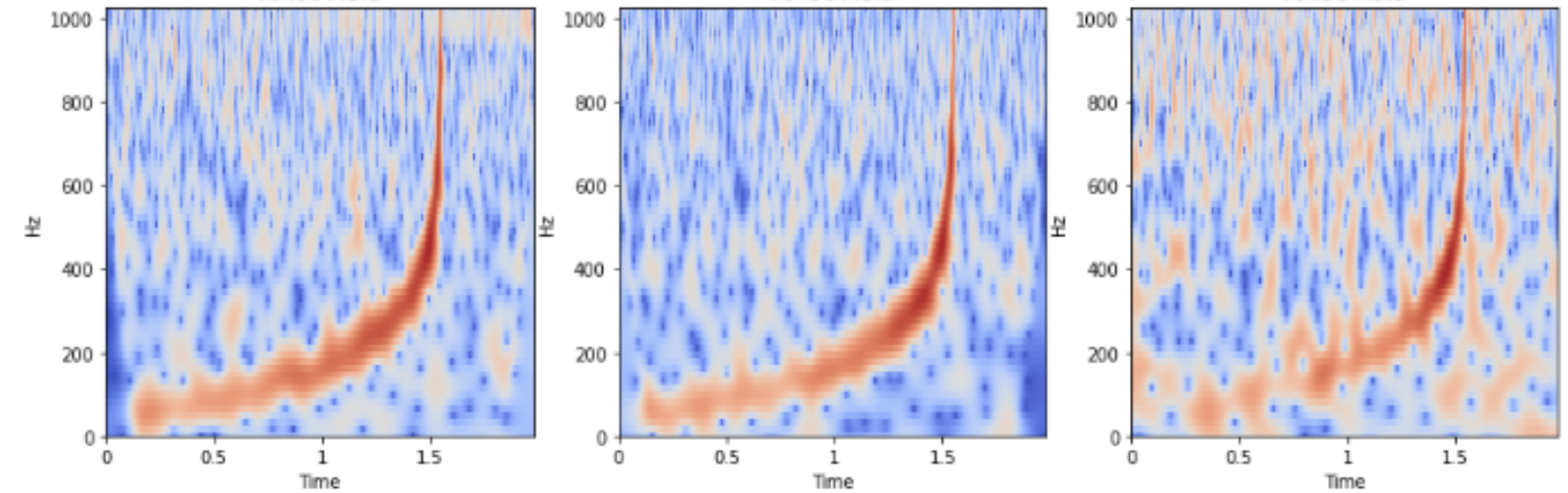
It is often hard to find a large collection of correctly labelled data. This scarcity of labelled real data exists for gravitational waves as well. One way to combat this shortage is to train on simulated data and hope the trained model is useful for the real dataset as well. The success of such an approach is dependant on the quality of simulation. Astronomy doesn’t have a shortage of raw data. So, I felt the application of semi-supervised training approach is particularly relevant for this task. One of the main components of semi-supervised training is the augmentation scheme. However in my experiments I found that it extremely difficult to come up with a good augmentation for this dataset. While thinking how to augment the data such that the signal characteristic is preserved, I realized that we already have an augmented dataset! My main insight was that whenever there is a gravitational wave, all three detectors must detect it. So, we can imagine that we have access to augmented versions of the same signal. The different geographical position and noise characteristic already takes care of the augmentation :-)
Useful links:
I have setup a kaggle notebook that you can use to get started easily if you are new to the competiation or don’t want to download the dataset (around 80GB).
Training details:
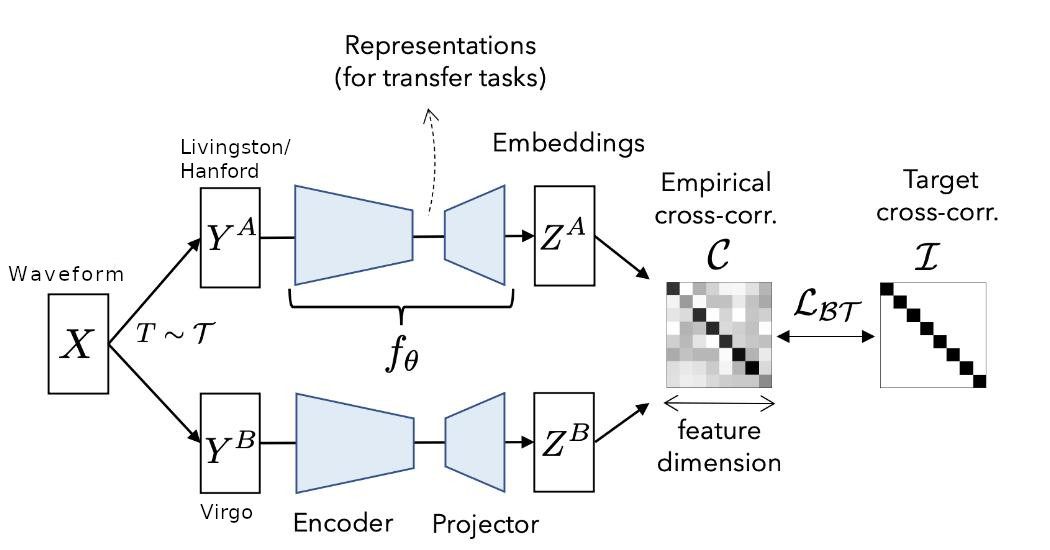
I used the recently proposed Barlow Twins method for semi-supervised training. I would highly recommend going through the paper to understand the details. The basic idea is to have two models which see different versions of data (in our case the gravitational wave signal) and use the barlow twin’s objective function to learn embeddings. While training on imagenet, people generally use cropping, flipping, blurring, random contrast etc to create different versions of the same image. In our case, we can feed the data from Hanford/Livingston into Net 1 and data from the Virgo detector into Net 2. Since the noise in Virgo detector is quite different from Hanford/Livingston, we can imagine it as an augmented sample of the same underlying signal.
There are many approaches (SimCLR, BYOL etc) for semi-supervised training. However, I found the simplicity of barlow twins approach quite appealing so I decided to try it first. Below is the pseudo code taken from the paper. It can be seen that the proposed loss can be implemented in just a few lines in pytorch.

Currently most semi-supervised work is focused on images. So, usually inputs are images and 2D CNN is used as model. However, for faster training I decided to train using waveforms. I trained a 1D CNN model inspired by this post. I observed that adding a GRU layer and reducing the original pooling size led to better results. I also removed the final fully connected layers since we require the models to produce embeddings. The bandpassed waveforms are fed as input to the model and we get embeddings of size 2048 as output. The output embeddings produces by both the networks are normalized along the batch dimension and we calculate the invariance and redundancy reduction terms. Using these terms, we get the final loss used for training the networks. In the original paper, they used LARS optimizer but I found that AdamW with an initial learning rate of 1e-4 also works. (I haven’t tried LARS optimizer yet, so maybe it will work even better.) Currently, I am only using pycbc generated noise as an additional augmentation.
Evaluation details:
After training the 1D CNN based model, we are able to get embeddings of the input waveform. Now, we need to train a Fully connected (FC) layer to make final prediction. For this we obtain embeddings for all the three detectors. Embeddings for Hanford/Livingston are obtained from Net 1 and Net 2 provides the Virgo embedding. The concatenation of all the embeddings is used as input to the FC layer. During the FC layer training, we freeze the backbone layer weights (net 1 & 2) and only train the FC layer on a subset of training dataset (i used 25% of the dataset). It is sufficient to train FC layer for 7-8 epochs. Once the FC training is complete, we can use the model to detect GW.
Things to try:
- Try this semi-supervised approach with 2D CNN model. In this case, instead of using direct waveforms we can use the extracted CQT features.
- Different 1d CNN architectures.
- New Augmentations
- Tuning the lambda parameter in barlow twins loss
Code details
If you have downloaded the dataset then it should be possible to easily replicate my results. In the repo, you will find a file called train.py. This can be used for training of the backbone model that is used for obtaining embeddings from the waveform. eval.py can be used for training the fully connected layer and also for local validation. Please note that you may need to adjust filepaths based on your setup.
cnn_models.py contains the pytorch based 1D CNN model.